Predicting muscular failure with ML!
Somehow I convinced CS students to do 3,200 bicep curls for science.
February 10, 2026
In my last year of uni I took a course called Machine Learning Practical which, as the name probably suggests, entails making your own ML model.
We could've picked literally any big dataset and rolled with it but unfortunately (or fortunately) I convinced my project partner @tomasmaillo that it would be cool if we made a model to predict muscular failure and built our own dataset. This turned out to not be the smartest decision we've ever made given this was 5 credits out of a 240 credit degree.
At least now I can write a blog post about how we managed to apply for ethics approval, convince random students to perform 3,200 bicep curls and make a model and paper that got us a high grade in 2 weeks. So here goes.
Step 1 - What's the idea?
We wanted to build a computer vision model that would watch you perform a strength training set, count your reps and warn you when you're on your last completable rep before you attempt another one. Exercises such as bench presses can be pretty dangerous and lots of people do them without having a spotter, so we thought it could be pretty impactful. Plus, if the model could tell you "you still have 10 reps left, keep going" it might encourage you to keep pushing instead of giving up early.
What we needed to do was:
- Get videos of people performing a set of an exercise till failure (we ended up choosing bicep curls)
- Use existing pose estimation algorithms to extract their joint movements (shoulder, elbow, hand as coordinates in time series data)
- Segment the joint movement data into individual reps (so each data point represents a single rep)
- Train an ML model to process these reps sequentially, and output an estimation of how many reps are left till failure at each step
Step 2 - Find a dataset
Excited and ready to go, we started looking for a suitable dataset. But of course, there is no suitable dataset. Where can we possibly find videos of people performing bicep curls where the shot is clean enough to train a model? We tried looking on Youtube, but no luck.
This is where we probably should've pivoted to another idea but instead I managed to convince my teammate that we should just build our own. I figured as long as we got around 1000 reps, that should be enough signal to build a decent-ish small model.
Step 3 - Get bicep curling!
We started by individually performing lots of bicep curl sets till failure (note: the sets had to be till failure, as the whole goal of the model is to predict how far away failure is)
Though we were getting lots of bicep gains, we also knew this wasn't going to scale as there's only so many sets we could do in a day. Besides, we didn't want the model overfitting to us. We knew we needed to bring more people in.
But turns out if you want to build your own dataset, you need your university to sign off on it being ethically fine. By the time we finally got approval, we had 2 weeks left till the deadline (we had 3 months to do this)
Step 4 - Convince other people to do bicep curls
Now the hard part. Getting people to answer a survey is hard enough, now try getting them to do exercise for you. Not easy. Fortunately we are expert marketers:

I will admit the poster was a little bit clickbait. We didn't exactly have the funds to give each person who performed a set for us a £40 Amazon gift voucher. Instead, we established that each set you perform till failure counts as one entry into a lottery to win a £40 gift voucher. So, if you perform 10 sets for us, your chance of winning is 10x higher than someone who does one set. The number of reps you perform doesn't matter, as long as you're hitting failure (though we had a minimum of 5 reps).
Step 5 - Head to the CS building

We were slightly stressed that we had left this too last minute so we wasted no time. We knew we needed a lot of people doing a lot of bicep curls fast. We considered going to the university gym, but we figured interrupting people mid workout to fill in an ethics form and do curls was unlikely to go well. So instead, we headed to Appleton Tower, Edinburgh's Computer Science building.
How are you going to have weights in a university building? Luckily for us I had recently purchased a pair of adjustable dumbbells that range from 1.5-18kg so I could workout at home.
So on a rainy Thursday in March we dismantled my dumbbells, packed them into two suitcases and lugged them with considerable effort to Appleton Tower. We set up a little kiosk next to the uni cafe/lunch area, armed with weights, phones to record sets, and 2 iPads for participants to sign consent forms.
Step 6 - Watch a queue form
Believe it or not, in a matter of minutes the kiosk was getting a lot of attention. It intrigued people enough to ask us what we were doing, and the posters in the lifts attracted dozens of people hoping to score an Amazon voucher. Before we knew it, we had queues of people signing consent forms and performing sets for us. People made alliances where they did 10 sets each and agreed to split the money if they won. Some came back multiple times during the day between lectures. We were open for 5+ hours straight, and when we closed there were still people trying to get a last set in.
It was so popular we decided to do a whole other day of data collection:

By the end of the two days, we had collected 254 unique sets performed till failure from 66 individuals, comprising 3200 reps.
Step 7 - Actually build the model
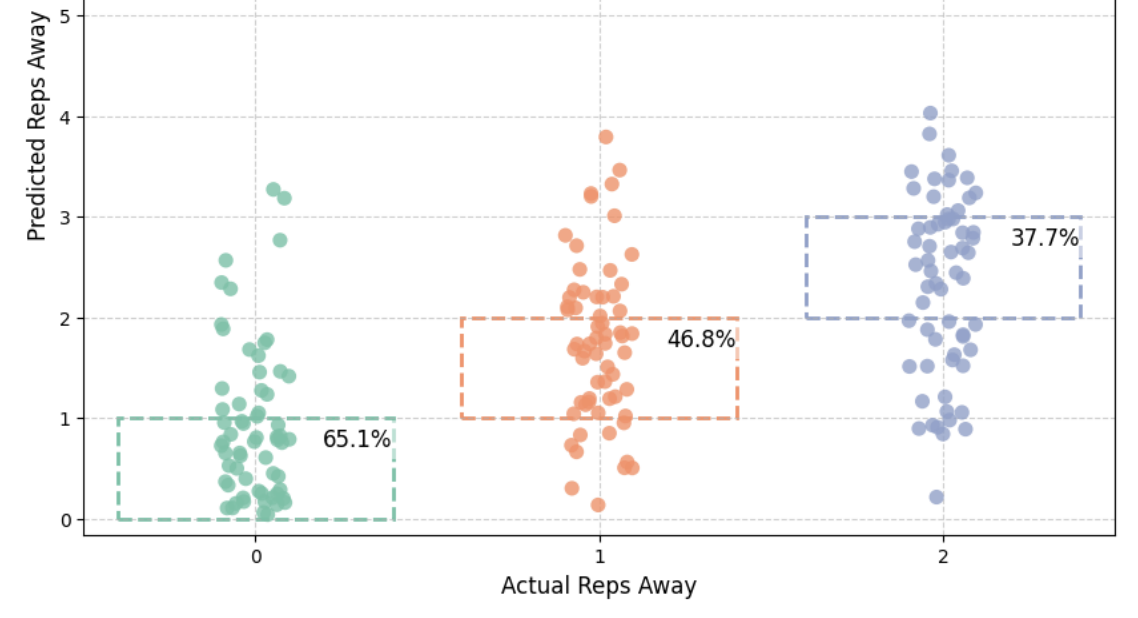
We now had 8 days left till the deadline to actually build the model and write a 12 page paper. We built a hierarchical LSTM with a custom loss function that penalises premature alerts and missed failure detection.
@tomasmaillo has an excellent write up which includes diagrams and our final paper, so I recommend you check that out if you're interested.

So how did the model do? It did okay, outperforming the baseline linear regression model we built by a lot, but there is certainly lots of room for improvement (see paper for a more detailed breakdown). This is in large part due to the fact that our dataset is still pretty small, so there was always going to be an upper bound on how well we'd be able to predict failure.
Step 8 - Result
We ended up getting a grade in the 70s for a course where the average is somewhere in the 50s, so we were pretty happy with that!
We also randomly selected a winner of our lottery, who ended up being someone who'd only done one set, with a 1/254 = 0.4% chance!
Overall, my learnings from this project were:
- Ethics approval takes a long time
- Building your own dataset is hard
- Students will do exercise for an Amazon voucher
Jokes aside, it was a lot of fun.